Spregledana kulturna dediščina in uporaba digitalne raziskovalne infrastrukture za humanistiko v raziskavi Odlivanje smrti
Andrej Pančur[os.]
Alenka Pirman[os.]
Maruša Dražil[os.]
V prispevku je predstavljeno sodelovanje med raziskovalci projekta Odlivanje smrti (TRACES) in Raziskovalno infrastrukturo slovenskega zgodovinopisja pri uporabi kulturne dediščine iz različnih ustanov za varstvo kulturne dediščine (GLAM – galerije, knjižnice, arhivi, muzeji) v raziskovalne namene.* Sodelovanje je potekalo v skladu z življenjskim ciklom raziskovalnih podatkov, ki je bil povsem prilagojen potrebam raziskave. Največji izziv je predstavljala standardizacija. Pri vključitvi zbirke digitalnih objektov (posmrtnih mask) v portal Zgodovina Slovenije – SIstory se je uporabil Dublin Core aplikacijski profil. Pri izdelavi digitalne izdaje smo uporabili smernice TEI in LIDO. S pomočjo javne predstavitve vmesnih rezultatov projekta smo začeli uspešno zbirati še dodatne objekte kulturne dediščine.
Uvod
Raziskave v humanistiki in umetnosti večinoma temeljijo na analizah različnih sledi človekovega delovanja, ki jih hranijo ustanove s področja varstva kulturne dediščine, kot so galerije, knjižnice, muzeji in arhivi.8 V tem oziru predstavlja dostop do kulturne dediščine velik izziv za bodoč uspešen razvoj digitalne humanistike. Kakovostni podatki in metapodatki o kulturni dediščini so nujen predpogoj za izvajanje zanesljivih, uspešnih in preverljivih raziskav na številnih področjih humanistike in umetnosti.9
Digitalna raziskovalna infrastruktura za umetnost in humanistiko DARIAH je zato leta 2016 sprožila pobudo10 za razvoj listine o ponovni uporabi podatkov kulturne dediščine (Cultural Heritage Data Reuse Charter), ki so se ji kmalu pridružile še ostale evropske organizacije (APEF, CLARIN, Europeana, E-RIHS) in projekti (Iperion-CH, PARTHENOS).11
Ta pobuda namerava vzpostaviti načela in mehanizme za uporabo in ponovno uporabo podatkov o kulturni dediščini v raziskovalne namene. Pri tem priporoča, da tako raziskovalci kot ustanove, ki hranijo kulturno dediščino, upoštevajo sledeča splošna načela:12
- recipročnost: obe strani dajeta druga drugi na razpolago svoje podatke in raziskovalne rezultate;
- interoperabilnost: to vsebino dajeta obe strani na razpolago v skladu z mednarodnimi standardi in interoperabilnimi protokoli;
- odprtost: po možnosti naj bodo podatki dostopni pod odprtimi pogoji;
- skrbništvo: poskrbi naj se za dolgoročno hrambo in dostop do vseh verzij podatkov in rezultatov;
- zanesljivost: jasno naj bodo razvidni njihov izvor, dokumentacija, tehnologija, procedure, protokoli, celovitost;
- citiranost: poskrbeti je treba za njihovo citiranost.
Dokler ta ambiciozna načela ne bodo splošno sprejeta, bodo raziskovalci za pridobivanje želenih virov in podatkov o kulturni dediščini še vedno potrebovali ogromno časa, volje in potrpežljivosti. Kljub temu pisci tega prispevka menimo, da raziskovalcem ni treba zgolj čakati, kdaj bodo raziskovalne in kulturne ustanove začele izvajati ta načela in podpisovati ustrezne listine, temveč lahko s svojo raziskovalno dejavnostjo v skladu z zgornjimi načeli že sami pomembno prispevajo k ustvarjanju primerov dobrih praks ter na ta način krepijo zaupanje med raziskovalci in ustanovami, ki hranijo kulturno dediščino. Pri tem se lahko raziskovalci zanašajo na aktivno pomoč digitalnih raziskovalnih infrastruktur za humanistiko.
V nadaljevanju bomo kot primer takšnega sodelovanja predstavili raziskavo Odlivanje smrti, ki jo je Društvo za domače raziskave skupaj s sodelavci iz različnih kulturnih ustanov opravljalo v okviru evropskega projekta TRACES. Podatke o kulturni dediščini, ki so zajeti v to raziskavo, so raziskovalci nato v skladu z digitalnohumanističnimi metodami obdelovali v sodelovanju z Raziskovalno infrastrukturo slovenskega zgodovinopisja z Inštituta za novejšo zgodovino. Ker ima življenjski cikel raziskovalnih podatkov ključen pomen v digitalni humanistiki,13 smo v skladu s tem ciklom strukturirali tudi podajanje vsebine v tem članku. Zaradi velike količine različnih definicij življenjskega cikla raziskovalnih podatkov smo se odločili v rahlo prilagojeni obliki (slika 1) prevzeti tisto, ki najustrezneje odraža delovanje raziskovalne skupine in raziskovalne infrastrukture v tukaj opisanem projektu.14
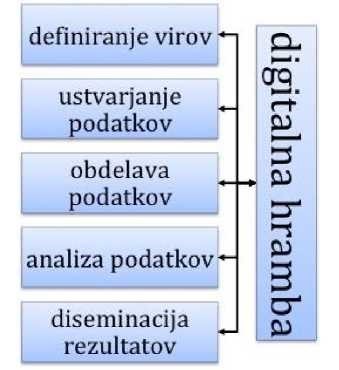
V drugem poglavju bomo predstavili vsebinsko zasnovo raziskave in vire, ki smo jih pri tem uporabili. V tretjem poglavju bomo opisali pridobivanje in ustvarjanje podatkov o kulturni dediščini. V četrtem poglavju o obdelavi podatkov bodo predstavljeni podatkovni model digitalnih objektov, uporabljeni metapodatkovni standardi in način dostopa. V nadaljevanju bo v šestemu poglavju z analizo podatkov sledilo poglavje o diseminaciji v obliki razstave. V zaključku bomo orisali še svoje načrte za ponovno uporabo teh raziskovalnih podatkov skupaj z njihovo nadaljnjo obdelavo, analizo in diseminacijo. Treba se je namreč zavedati, da tukaj predstavljeni življenjski cikel raziskovalnih podatkov ni enosmerna pot od definiranja virov do diseminacije raziskovalnih rezultatov, ki se konča s hrambo raziskovalnih podatkov in rezultatov v ustreznih digitalnih repozitorijih, temveč so vsi ti procesi med seboj v interaktivnem odnosu.
Vsebinska zasnova raziskave
Raziskava Odlivanje smrti je potekala v okviru triletnega evropskega projekta TRACES15, ki ga je financirala Evropska komisija (Obzorje 2020). Društvo za domače raziskave je v njem sodelovalo kot partner, koordinirala pa ga Univerza v Celovcu. Projekt je želel preseči uveljavljeno prakso umetniških intervencij in je posebno pozornost posvečal razvoju metodologij sodelovanja. Jedro raziskovalnega projekta je bilo pet interdisciplinarnih umetniško-raziskovalnih delovnih skupin, ki smo jih poimenovali “ustvarjalne koprodukcije”, v njih pa so enakopravno sodelovali umetniki, znanstveniki in upravljavci kulturne dediščine. Ustvarjalna koprodukcija s sedežem v Ljubljani se je na primeru posmrtnih mask ukvarjala z vlogo umetnika pri posredovanju sporne kulturne dediščine, kar je bila tudi krovna tema celotnega projekta.
Odlivanje posmrtne maske je ena najstarejših portretnih kiparskih tehnik.16 V 19. stoletju je postala še posebej priljubljena, saj je sovpadla z družbenim uveljavljanjem meščanskega razreda, pri čemer so ključno vlogo odigrali tudi muzeji.17 Izhajali smo iz teze, da posmrtne maske za skupnost pomembnih osebnosti delujejo kot eksploatacijski medij, vpet v natančno strukturirane politične in družbene projekte (nacionalizem, razredni boj, sekularizacija), in iz opažanja, da je javno življenje posmrtnih mask v zatonu in da se ob prenovah muzejskih postavitev umikajo v depoje. Zanimalo nas je, koliko posmrtnih mask sploh hranijo javne zbirke po Sloveniji in kdo pravzaprav so ti ljudje, katerih obličja so bila odlita za javni namen.
Izkazalo se je, da tovrstna raziskava še ni bila opravljena in da podatki javnosti niso na voljo. V prvi fazi smo opravili sondaže v izbranih muzejih (Muzej in galerije mesta Ljubljane, Muzej novejše zgodovine Slovenije, Moderna galerija ter Narodna in univerzitetna knjižnica). Na podlagi ogleda gradiva v depojih, pogovorov s kustosi posameznih zbirk ter primerjave z obstoječimi kataložnimi zapisi smo že identificirali vrsto problemov, vezanih na podatke o posmrtnih maskah. Ti so identifikacija upodobljencev (neznani ali različno atribuirani odlitki), določanje avtorstva (različne atribucije; nejasni podatki za tehnološke različice), nejasna provenienca gradiva, ločevanje »originala« od kopij ipd. Večino navedenih težav pripisujemo dejstvu, da slovenske dediščinske institucije posmrtnih mask niso zbirale načrtno, pač pa so te v zbirke zašle po različnih poteh, iz reakcije skrbnikov teh zbirk pa utemeljeno sklepamo, da so bile posmrtne maske doslej dejansko spregledana kulturna dediščina.
Za drugo fazo raziskave smo sestavili nabor 114 kulturnih in znanstvenih organizacij (muzejev, arhivov, knjižnic, galerij, gledališč, inštitutov), ki bi utegnile hraniti posmrtne maske, ter z njimi sistematično navezali stike. Obenem smo zaradi kompleksnosti naloge in v želji po zagotovitvi trajne hrambe podatkov po zaključku evropskega projekta vzpostavili sodelovanje med Društvom za domače raziskave in Inštitutom za novejšo zgodovino, v okviru katerega deluje Raziskovalna infrastruktura slovenskega zgodovinopisja. Sodelovanje je omogočilo koncipiranje zbiranja podatkov o izbranem gradivu. Tak način se je izkazal kot dober metodološki pripomoček, ki je že od začetka vplival na potek raziskave.
Ustvarjanje raziskovalnih podatkov
Sodelovanje med digitalno humanistiko in ustanovami s področja varstva kulturne dediščine temelji na konceptu upravljanja s podatki, kjer glavno vlogo igrajo digitalni nadomestki. To so informacijske strukture, ki identificirajo, dokumentirajo ali predstavljajo primarne vire, ki se uporabljajo v raziskovalnem delu.18 Digitalni nadomestki torej niso le digitalne fotografije originalnega analognega gradiva, ki ga večinoma hranijo knjižnice, muzeji, arhivi in galerije, temveč tudi metapodatkovni zapisi, prepisi besedil, označevanje strukture in vsebine besedil, digitalne anotacije oziroma kakršnokoli pridobivanje novih podatkov ali pretvorba obstoječih podatkov.
Zbiranje podatkov in fotografij je dolgotrajen in zahteven proces. Izbor javnih institucij, ki so bile povabljene k sodelovanju, teži k temu, da je številčno čim bolj obsežen, hkrati pa upošteva tudi različnost tipov (kulturnih) ustanov. Ta dva kriterija sta pri koncipiranju seznama institucij ključna predvsem zaradi dejstva, da ni vzorca, po katerem bi lahko predvideli, kje bo koncentracija teh predmetov največja. Odločitev, da bo glavni poudarek predvsem na kulturnih ustanovah, izhaja iz razumevanja temeljne funkcije posmrtnih mask, ki je ohranjanje spomina na pokojnika, procesi zgodovinjenja pa se v prvi vrsti odvijajo prav v muzejih, spominskih sobah, domoznanskih oddelkih splošnih knjižnic ipd.
Začetni nabor institucij se je tekom raziskave postopoma spreminjal: nekatere ustanove so bile izločene iz prvotnega seznama, druge spet dodane. Na podlagi naključno pridobljenih informacij o lokacijah posmrtnih mask (pričevanja obiskovalcev razstave, zaposleni v raznih ustanovah, pisni viri) so se na seznam uvrstile nekatere nove institucije (skupno 118).
Ker so posmrtne maske predmeti, ki so v našem prostoru relativno slabo strokovno obdelani, poleg tega pa so pogosto javnosti tudi nedostopni (v večini primerov hranjeni v depojih), so podatki, ki jih posedujejo njihovi lastniki oz. skrbniki, ključnega pomena za nadaljnje raziskovanje in interpretiranje tega fenomena. Izkazalo se je, da se je skozi čas precejšen del podatkov o posmrtnih maskah izgubil. Ustanove namreč pogosto posredujejo le tiste podatke, ki so jih o maskah vzpostavile same (inventarno številko, tehniko, nahajališče, dimenzije, stanje), podatki o provenienci so v večini primerov skopi oziroma jih sploh ni, prav tako pa je zelo malo znanega o (širšem) kontekstu nastanka posamezne maske. Precej dvoumnosti se pojavlja tudi na področju identificiranja upodobljencev in avtorjev posmrtnih mask.
| Metapodatek | Ustanove | |
| št. | v % | |
| upodobljenec | 31 | 100 |
| avtor | 24 | 77,4 |
| tehnika | 18 | 58,1 |
| datacija | 14 | 45,2 |
| inventarna številka | 17 | 54,8 |
| nahajališče | 23 | 74,2 |
| provenienca | 20 | 64,5 |
| dimenzije | 13 | 41,9 |
| stanje | 7 | 22,6 |
| ohranjenost | 1 | 3,2 |
| število kopij | 2 | 6,5 |
| viri | 1 | 3,2 |
Po letu in pol intenzivnega poizvedovanja je podatke o številu posmrtnih mask v svojih zbirkah posredovalo dobrih 50 % vseh vprašanih ustanov, kar pomeni 32 muzejev in galerij, 19 knjižnic, 3 gledališča, 4 spominske sobe/hiše ter 6 različnih kulturnih institucij, ki ne sodijo v nobeno od prej naštetih kategorij (SAZU, Cankarjev dom, AGRFT idr.). Fotografije teh posmrtnih mask je imelo 19 ustanov, izmed katerih so nekatere prav zaradi naše raziskave maske šele prvič tudi fotografirale. V primeru osmih ustanov so maske fotografirali šele raziskovalci. V nekaterih primerih mask ni bilo mogoče fotografirati, mdr. tudi zaradi tega, ker so bile v preveč slabem stanju.
Obdelava raziskovalnih podatkov
Člani raziskovalne skupine, ki smo digitalne nadomestke pridobili od zgoraj navedenih javnih zavodov, le-teh nismo mogli takoj uporabiti v svoji raziskavi, temveč smo jih morali za potrebe svoje raziskave najprej primerno obdelati. Kot smo videli, pridobljeni metapodatki namreč niso bili nujno narejeni po enotnih standardih, predvsem pa so bili s stališča izvajanja raziskave v mnogih primerih tudi pomanjkljivi oziroma neprimerni. Ustanove s področja varstva kulturne dediščine glede na svoje poslanstvo z ustvarjanjem digitalnih nadomestkov praviloma zadovoljujejo potrebe širše javnosti, ki se zanima za kulturno dediščino, in ne delujejo v skladu s specifičnimi interesi posameznih raziskovalnih skupin in ne odgovarjajo na njihova projektna vprašanja. Te interese v prvi vrsti pokrivajo raziskovalne infrastrukture.19
Podatkovni model
Obenem je bilo precej posmrtnih mask dostopnih samo v analogni obliki, zato smo morali veliko digitalnih nadomestkov najprej šele ustvariti. V skladu z raziskovalnimi praksami v digitalni humanistiki smo se odločili, da za digitalne nadomestke ustvarimo podatkovni model, ki bo povsem ustrezal specifičnim raziskovalnim potrebam našega projekta. Podatkovni model ni opis realnega sveta, temveč je interpretacija (analognega) objekta. Podatkovno modeliranje je v prvi vrsti ustvarjalen in kreativen proces, pri čemer funkcija digitalnega nadomestka določa, katere aspekte je treba modelirati.20
Raziskovalna skupina se je odločila ustvariti zbirko digitalnih objektov (posmrtnih mask), v kateri ima vsak digitalni objekt nič ali več digitalnih fotografij in sledeče metapodatke:21 naslov digitalnega objekta, opis, podatke o tem, kdo je upodobljenec, avtor maske, naročnik, podatke o letu naročila, verziji odlitka, številu znanih odlitkov, tehniki, instituciji/lokaciji, zbirki/nahajališču, inventarni številki, stanju predmeta in oznaki, provenienci/zgodovini predmeta, virih (in literaturi).
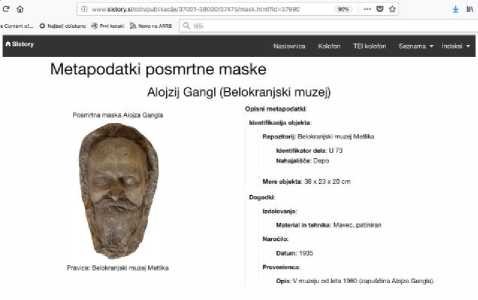
Ta podatkovni model je po eni strani relativno zelo enostaven. Lahko rečemo, da je povsem običajen glede dojemanja kulturne dediščine, zato smo ga lahko tudi relativno enostavno kot zbirko digitalnih objektov vključili v portal Zgodovine Slovenije – SIstory, ki ga upravlja Raziskovalna infrastruktura slovenskega zgodovinopisja.22 Digitalna zbirka omogoča iskanje in brskanje po digitalnih objektih ter pregled vseh metapodatkov in digitalnih fotografij.23
Vendar ima ta enostavni podatkovni model tudi nekatere pomanjkljivosti, ki bi lahko imele negativen vpliv na nadaljnji potek raziskav. Pri zapisih metapodatkov o upodobljencih, avtorjih mask in pogojno tudi naročnikih smo prvotno pri vsakem digitalnem objektu zapisovali imena in priimke teh oseb, njihove poklice ter datume rojstva in smrti. Takšna rešitev je imela sledeče pomanjkljivosti:
- oseba je lahko imela več kot en poklic;
- če je bila ista oseba prisotna pri več kot enem digitalnemu objektu, bi bilo pri napačnih ali pomanjkljivih zapisih treba iste spremembe vnašati pri vseh teh objektih;
- podobno bi bilo treba nove vrste metapodatkov (npr. spol, kraj rojstva ali smrti) o posamezni osebi enotno vnesti pri vseh digitalnih objektih, kjer je ta oseba omenjena.
Iz tega razloga smo se odločili, da prvotni podatkovni model dopolnimo z dodatnimi entitetami. Poleg osnovne entitete object (objekt: posmrtna maska) smo v podatkovnem modelu začeli uporabljati še entiteto person (oseba), v načrtu pa imamo še razširitev podatkovnega modela z entitetama organization (javni zavod, ki hrani posmrtno masko) in place (kraj rojstva in/ali smrti). Relacije med objektom in osebo so lahko treh vrst (type): subject (oseba, ki je predmet upodobitve: upodobljenec), production (oseba, ki je izdelala masko: avtor) in commissioning (oseba ali organizacija, ki je naročila izdelavo maske: naročnik).
Standardizacija
V naslednjem koraku smo se odločili, da bomo specifičen podatkovni model svoje raziskave v čim večji možni meri uskladili z obstoječimi standardi na področju humanistike in umetnosti. S hitrim naraščanjem količine digitalnega gradiva v humanistiki in umetnosti je standardizacija praktično postala nuja za vse raziskovalce, ki želijo svoje digitalne podatke deliti ali jih primerjati z ostalimi podobnimi digitalnimi podatki. Ker pa je standardizacijo mogoče uspešno izpeljati samo na podlagi ustreznega tehnično-strokovnega znanja, se ji raziskovalci s področja umetnosti in humanistike pogosto poskušajo izogniti.24 V primeru naše raziskave nam je uspelo standardizacijo izpeljati relativno hitro in enostavno. Pri tem smo se oprli na obstoječe postopke in izkušnje raziskovalne infrastrukture.
Portal SIstory podobno kot veliko ostalih digitalnih knjižnic uporablja zelo razširjen Dublin Core metapodatkovni standard. Zaradi specifičnih potreb tega portala smo v Raziskovalni infrastrukturi slovenskega zgodovinopisja razvili aplikacijski profil, ki sloni na razširjenem standardu Dublin Core (DCMI Metadata Terms).25 Po vzoru projekta HOPE26 smo mu dodali še nekatere elemente iz drugih metapodatkovnih shem, ki so potrebni pri opisu arhivskih, knjižničarskih, muzejskih in avdiovizualnih objektov.27 V okviru raziskave Odlivanje smrti so se za zelo primerne izkazali elementi iz sklopa muzejskih metapodatkov, ki smo jih prevzeli iz LIDO28 in Spectrum29 metapodatkovnih standardov. Natančneje je ta standardizacija prikazana v spodnji tabeli:
| Standard | Element | Opis |
| DCMI | title | naslov objekta |
| DCMI | description | opis objekta |
| DCMIType | type | tip objekta: Physical Object |
| DCMI | creator | avtor maske |
| DCMI | contributor | naročnik |
| DCMI | created, date | leto naročila oz. izdelave |
| DCMI | hasVersion, isVersonOf | relacije med verzijami |
| LIDO | eventMaterialsTech | tehnika |
| SIstory | collection | ustanova analogne maske |
| DCMI | accessRights | zbirka/nahajališče |
| DCMI | identifier | inventarna številka |
| Spectrum | TechnicalAttributes | stanje objekta |
| LIDO | objectMeasurement | velikost objekta |
| DCMI | provenance | provenienca |
| DCMI | bibliographicCitation | viri in literatura |
Z razširitvijo podatkovnega modela z entiteto person obstoječi metapodatkovni aplikacijski profil portala SIstory ni več ustrezal vsem potrebam raziskave Odlivanje smrti. SIstory za upravljanje metapodatkov uporablja MySQL relacijsko bazo podatkov. Relacijske baze podatkov so sicer najpogosteje uporabljena tehnologija baz podatkov30 in so zlasti primerne za upravljanje velike količine medsebojno povezanih entitet, kot so osebe, predmeti, procesi ipd. Toda po drugi strani je pri relacijskih podatkovnih bazah treba vnaprej določiti strukturo njenih podatkov, podatkovno shemo in podatkovne tipe. Vse naknadne spremembe so zelo zahtevne in jih je treba skrbno načrtovati.
Podobno kot pri mnogih digitalnohumanističnih projektih je tudi pri naši raziskavi podatkovni model prilagojen specifičnim potrebam raziskave, hkrati pa mora biti dovolj fleksibilen za dodatne nadgradnje podatkovnega modela v skladu z vedno novimi raziskovalnimi vprašanji. Namesto preveč toge relacijske baze podatkov portala SIstory smo zato raje uporabili veliko fleksibilnejšo XML podatkovno strukturo.
V ta namen smo v okviru raziskovalne infrastrukture razvili postopek, ki omogoča pretvorbo podatkov iz datotek XML v statične HTML spletne strani in njihovo vključitev v portal SIstory. Pri kodiranju datotek XML uporabljamo Smernice Text Encoding Initiative (TEI).31 Smernice TEI so predvsem v digitalni humanistiki de facto standard za kodiranje besedil. Smernice med drugim vključujejo tudi modul za kodiranje imen, datumov, oseb in krajev. Ta modul smo uporabili za kodiranje podatkov o osebah (o entiteti person našega podatkovnega modela), v bodoče pa ga nameravamo uporabiti še za kodiranje entitet organization in place. V našem primeru je bila odločitev za uporabo TEI še toliko lažja, ker je večina oseb iz naše raziskave vključena v Slovensko biografijo,32 ki za kodiranje podatkov o osebah tudi uporablja TEI.33 Te podatke smo zato lahko samo z manjšimi spremembami relativno enostavno vključili v svojo raziskavo.
Dokument TEI raziskave Odlivanje smrti vsebuje dva seznama entitet projektnega podatkovnega modela (object in person). Oba seznama sta kot <div> vključena v element <body>. Seznam oseb <listPerson> vključuje elemente <person> s podatki o osebah našega podatkovnega modela. Ta element nato vsebuje enega ali več elementov za kodiranje vseh možnih različic osebnih imen te osebe (<persName>), kodiranje vrednosti za spol osebe <sex> (vrednost atributa @value M za moške in F za ženske), podatke o enem ali več poklicih <occupation>, podatke o rojstvu <birth> in smrti <death> ter nenazadnje URL identifikator <idno> spletnega mesta z dodatnimi metapodatki o teh osebah. Elementa o rojstvu in smrti lahko vsebujeta podatek o datumu <date> in kraju <placeName> rojstva ali smrti. Kot primer dobre prakse sodelovanja med raziskovalci in raziskovalnimi infrastrukturami smo od projekta Slovenska bibliografija prevzeli taksonomijo poklicev. Izvorno taksonomijo, ki ni javno dostopna, smo vključili v <teiHeader> svojega TEI dokumenta. Elementi <occupation> se na njo navezujejo po atributu @code.
Večji izziv kot kodiranje podatkov o osebah je predstavljala druga entiteta našega podatkovnega modela: object (posmrtna maska). TEI je namreč namenjen kodiranju besedil, ne objektov, zato predstavlja kodiranje objektno usmerjenih zbirk nebesedilne kulturne dediščine precejšen izziv.34 Mi smo se odločili uporabiti zaporeden seznam <list> objektov, kjer vsak objekt kot postavka <item> vsebuje svoj seznam glavnih metapodatkov. Ta seznam je kodiran kot glosar izrazov <item> in njihovih opredelitev <label>. Pri tem smo enotno kodirali samo sledeče opredelitve:
- naziv posmrtne maske: Dublin Core title element;
- avtorja maske: notranjo povezavo <ref> na element <person>;
- upodobljenca: notranjo povezavo <ref> na element <person>;
- SIstory: zunanjo povezavo <ref> na digitalni objekt te posmrtne maske v zbirki portala SIstory;
- LIDO metapodatke: zunanjo povezavo <ref> na LIDO metapodatke.
Ti seznami objektov torej poleg naslova vsebujejo samo reference na izvorne digitalne objekte portala SIstory, na ostale entitete (person), kodirane v TEI, in nenazadnje na vse metapodatke objekta posmrtne maske, ki smo jih kodirali v skladu s standardom LIDO. Ta standard je zlasti primeren za opisovanje muzejskih objektov, med drugim tudi analognega nebesedilnega gradiva, kot so posmrtne maske. Kot takšnega ga uporabljajo tudi sorodne raziskovalne infrastrukture s področja digitalne humanistike.35
Vsak objekt (digitalna maska) ima svojo datoteko XML z LIDO metapodatki. Za izdelavo teh metapodatkov uporabljamo izvoz metapodatkov o digitalnih objektih zbirke Odlivanje smrti iz SIstory relacijske baze podatkov v datoteko XML,36 ki jo potem s posebej napisanim programom XSLT pretvorimo v datoteke XML z LIDO zapisom. LIDO metapodatkovni zapis vsebuje identifikator <lidoRecID> (uporabljamo SIstory handle identifikator), kategorijo <category> (opredelimo, da je fizični objekt), opisne in administrativne metapodatke. Slednji vsebujejo podatke o zapisu (<recordWrap>), za katerega je v skladu z LIDO terminologijo37 določeno, da ta zapis opredeljuje posamezni objekt (Item-level record), ki ga je s SIstory identifikatorjem (<recordID>) prispevalo Društvo za domače raziskave (<recordSource>). Vsak tak objekt ima lahko tudi eno ali več fotografij (<resourceRepresentation>).
Najobsežnejši so opisni metapodatki
(<descriptiveMetadata>). Z njimi najprej klasificiramo (<objectClassificationWrap>) objekt kot posmrtno masko (<objectWorkTypeWrap>),38 ki upodablja konkretno
osebo (<classificationWrap>). Potem identificiramo objekt (objectIdentificationWrap>) z njegovim nazivom
(<titleSet>), ustanovo izvornega analognega gradiva (<repositoryWrap>), se pravi naziv ustanove
(<repositoryName>), signaturo (<workID>) in lokacijo hrambe (<repositoryLocation>) ter še različne vsebinske opise maske in njenega stanja (<objectDescriptionWrap>) ter njene mere (<objectMeasurementsWrap>).
Naposled sledi del (<eventWrap>), ki opisuje tri ključne dogodke (<eventSet>), povezane z objektom. Za označbo vrste (<eventType>) vsakega od njih se uporablja ustrezna LIDO terminologija.
Izdelovanje (production): vsebuje podatke o izdelovalcu (<eventActor>) maske in materialu, iz katerega jo je izdelal (<eventMaterialsTech>).
Naročilo (commissioning): vsebuje podatke o naročniku (<eventActor>) in datumu naročila (<eventDate>).
Provenienca (provenience): vsebuje opise vseh znanih menjav lastništva in hrambe maske.
Digitalna izdaja
Tako kodirani dokumenti TEI in LIDO so dostopni v GitHub repozitoriju.39 Za izdelavo HTML digitalne izdaje40 smo uporabili standardne pretvorbe XSLT konzorcija TEI,41 ki smo jih nadgradili v skladu s potrebami vključitve HTML statičnih spletnih strani v portal SIstory.42
Te generične pretvorbe XSLT je za vsako digitalno izdajo mogoče prilagoditi specifičnim potrebam posamezne raziskave. V okviru raziskave Odlivanje smrti smo to fleksibilnost sistema poskusili izkoristiti v čim večji meri in smo statičnim spletnim stranem dodali še nekatere dinamične funkcionalnosti. Za prikazovanje LIDO metapodatkov samo o eni posmrtni maski na posamezni spletni strani (unikatni URL) smo uporabili Saxon-JS.43
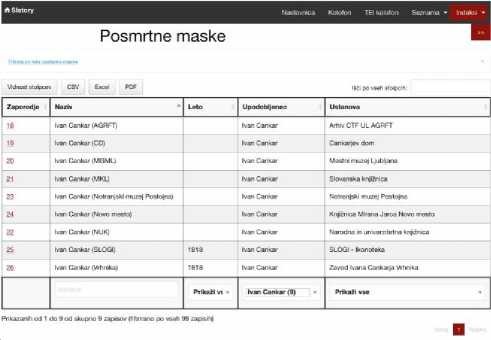
Za najbolj koristnega pa se je za potrebe naše raziskave izkazal odprtokodni vtičnik DataTables, namenjen jQuery JavaScript knjižnici.44 Z njegovo pomočjo smo HTML tabelam (Posmrtne maske, Osebe, Posmrtne maske z znanimi upodobljenci, Upodobljenci posmrtnih mask) dodali številne funkcionalnosti, ki so nam omogočale filtriranje, razporejanje, iskanje in izvažanje želenih podatkov (slika). S pomočjo teh tabel smo se lahko uspešno lotili naslednje stopnje življenjskega cikla podatkov – analize raziskovalnih podatkov.
Analiza raziskovalnih podatkov
S pomočjo teh tabel smo lahko zelo enostavno prišli do nekaterih rezultatov, npr. kdo je najpogostejši upodobljenec (Ivan Cankar[os.] – 9 kopij posmrtnih mask, gl. sliko 2) ali katera ustanova hrani največ posmrtnih mask (Mestni muzej Ljubljana – 17).
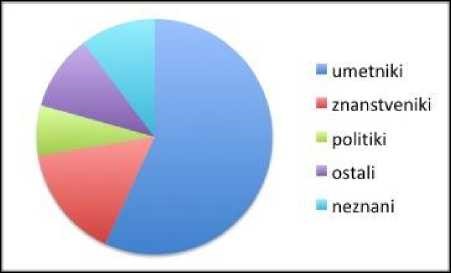
Za nekoliko bolj zapletene izračune pa te tabele omogočajo tudi izvoz vseh podatkov ali samo filtriranih v CSV format (za manj zahtevne uporabnike tudi Excel), ki ga nato lahko uporabimo v nadaljnjih statističnih izračunih v poljubnem statističnem programu. Na ta način smo tako izvozili podatke o vseh na prvem mestu navedenih poklicih upodobljencev. Te poklice smo nato klasificirali v skladu s preprosto shemo (slika).
Diseminacija rezultatov
Sredi triletnega raziskovalnega obdobja smo se odločili za javni prikaz delnih rezultatov raziskave. Pripravili smo razstavo,45 ki je fenomen posmrtnih mask predstavila v treh sklopih: Zbiranje, Odlivanje in Oživljanje. Prvi sklop je bil posvečen zbranim podatkom o historičnih posmrtnih maskah iz slovenskih javnih zbirk. Ker je bil odziv nagovorjenih institucij v času odprtja razstave le 55-odstoten, je bil eden od njenih namenov spodbuditi odziv še pri preostalih. Prvenstveno pa smo želeli javnost seznaniti z nekaterimi delnimi izsledki. Izbrali smo tri kriterije za prikaz baze podatkov v obliki infografik:
- posmrtne maske glede na poklic upodobljencev,
- upodobljenci z največjim številom posameznih odlitkov posmrtne maske,
- posmrtne maske po letu smrti.
Prvi statistični prikaz podpira teorijo o kulturnem svetništvu,46 saj je največ upodobljencev (več kot dve tretjini) umetnikov. Drugi kriterij je vzpostavil lestvico priljubljenosti posameznih osebnosti za nacionalno identiteto (z devetimi odlitki je na prvem mestu Ivan Cankar[os.], sledijo Rihard Jakopič[os.], Simon Gregorčič[os.], Oton Župančič[os.] in Ivan Levar[os.]). Najbolj pa je presenetil tretji prikaz, saj smo pričakovali, da bo največ upodobljencev s konca 19. in začetka 20. stoletja, ko je bila posmrtna maska kot medij najbolj priljubljena.47 Dejansko pa je največ mask v slovenskih javnih zbirkah iz 50. let 20. stoletja, čeprav sprememba režima ni bistveno vplivala na izbiro upodobljencev (politiki ostajajo redki, vseh skupaj je le 5 %).
Tako kot nastajajoča baza podatkov na portalu SIstory je bila tudi razstava zastavljena delovno, tj. nereprezentančno, in je sprožila različne odzive: obiskovalci so prispevali dodatne informacije o posmrtnih maskah v drugih zbirkah, z njihovo pomočjo nam je uspelo tudi identificirati 3 neznane upodobljence. Dober odziv medijev in institucij v nadaljevanju raziskave pa daje slutiti, da posmrtne maske odslej ne bodo več del spregledane kulturne dediščine.
Po večkratnih poizkusih smo naposled uspeli pridobiti podatke o posmrtnih maskah od 118 institucij (93 %) iz različnih delov Slovenije. Le 32 (27 %) izmed njih ima v svoji zbirki tovrstne predmete. Izkazalo se je, da so muzeji, galerije in spominske sobe (22 ustanov) najpogostejše lokacije, kjer se danes nahajajo maske, saj hranijo 66 % vseh evidentiranih mask, tj. 70 primerkov. Sledijo knjižnice (5 ustanov) – v njihovih depojih se nahaja 14 % vseh zabeleženih odlitkov oz. 16 primerkov. Dvajset pa jih je našlo svoje mesto v zbirkah drugih kulturnih ustanov: na Akademiji za gledališče, radio, film in televizijo (AGRFT) ter SAZU-ju, v Cankarjevem domu, na Slovenskem gledališkem inštitutu in v arhivu Studia Slovenica. V času trajanja projekta smo v slovenskih javnih zbirkah odkrili skupno 106 posmrtnih mask (vključno s kopijami), ki pripadajo 64 različnim upodobljencem.
Zaključek
Trenutno so delovne verzije zbirke digitalnih objektov in digitalne izdaje hranjene na portalu SIstory. Po zaključku projekta nameravamo končne verzije teh raziskovalnih rezultatov dolgoročno shraniti tudi v svoji aplikaciji Archivematica.48
Zaradi sprotnega nadgrajevanja in dopolnjevanja zbirke ter vmesnega objavljanja raziskovalnih rezultatov je treba imeti jasno zastavljeno vizijo in dober pregled nad različnimi verzijami zbirke raziskovalnih podatkov o kulturni dediščini. Vsaka od teh verzij je namreč zbirka novih digitalnih nadomestkov, zato smo se odločili, da bomo repozitorij portala SIstory nadgradili na način, ki bo omogočal dolgoročno in čim bolj trajnostno hrambo digitalnih izdaj. Raziskovalni rezultati projekta Odlivanje smrti nam v tem primeru služijo kot odličen testni primer.
* Gre za prilagojen in nekoliko dopolnjen članek, ki je bil prvič predstavljen na konferenci Jezikovne tehnologije in digitalna humanistika v Ljubljani (2018). Objavljeno v: Darja Fišer[os.] in Andrej Pančur[os.] (ur.). Zbornik konference Jezikovne tehnologije in digitalna humanistika. Ljubljana: Znanstvena založba Filozofske fakultete v Ljubljani, str. 203−210. Dostopno na: https://ebooks.uni-lj.si/zalozbaul//catalog/book/120, pridobljeno 11. 11. 2022. Raziskavo je sofinancirala Javna agencija za raziskovalno dejavnost Republike Slovenije v okviru programa Raziskovalne infrastrukture slovenskega zgodovinopisja (I0-0013) in slovenske raziskovalne infrastrukture DARIAH-SI ter projekta TRACES.
12. Cultural Heritage Data Reuse Charter: Mission Statement, b. n. s.
15. TRACES, Horizon 2020 project proposal.
21. Prim. Društvo za domače raziskave, Archives: Masks (prvotna poskusna postavitev baze posmrtnih mask na spletni strani DDR).
22. SIstory, Odlivanje smrti.
25. Dublin Core Metadata Initiative, DCMI Metadata Terms.
26. HOPE: Heritage of the People's Europe.
28. LIDO: Lightweight Information Describing Object.
29. Spectrum.
31. TEI Consortium, Guidelines.
32. Slovenska biografija.
37. LIDO-Terminologie.
38. Pri tem uporabljamo tudi Getty Art & Architecture Thesarus.
39. SIstory/Publications, Odlivanje smrti.
40. SIstory, Odlivanje smrti: Pregled objav na portalu.
41. TEI XSL Stylesheets.
42. SIstory TEI Stylesheets.
43. Saxon-JS.
44. DataTables.