Introduction
The initiative by the Slovenian Computer History Museum to organize a panel discussion on the legacy of informatization tools, of which software is the most important, has come at a very appropriate time. The year 1960 saw the first herald of the computer era in Slovenia, when a book by Professor France Križanič was published, Elektronski aritmetični računalniki (Electronic arithmetic computers), based on his experience with a Ural-1 computer at the Moscow State University (MGU). In 1962 the first computer in Slovenia was put to use, a Zuse Z23, and luckily quite a few of its users are still with us, to share their first-hand experiences.
In the paper the author’s post-mainframe software path is illustrated, involving text editors with language technology and corpus linguistic features, including a lexical web search engine. In the end the possibility of a Wikipedia-inspired solution to the presentation of his work as an online museum exhibit is discussed.
STRUCTRAN
At the end of the 1960s and even more in the early 1970s, it became clear that the programming languages of the day – in science and technology mostly FORTRAN, in business environment COBOL – were not entirely suited for the tasks they were used for. Long and complex programming tasks produced immense volumes of source code, which was increasingly difficult to update and maintain, all because these two programming languages were still closer to machine code, and not abstract, structured enough to work with easily. In 1968 Professor Edsger Dijkstra published a letter titled “Go To Statement Considered Harmful”. Jumping from place to place, up and down, such code does indeed make one lose any overview of the intentions of the programmer very quickly, and profoundly, even more so after returning to the same code some time – days, weeks or months – later. This led to so-called structured programming, coding without Go To statements but with control structures, which have a beginning and an end, such as IF ELSE ENDIF, loops with FOR ENDFOR, REPEAT ENDREPEAT, WHILE ENDWHILE.
As writing a new compiler is a long and cumbersome task, Vladimir Batagelj from the Department of Mathematics at the Faculty of Natural Sciences and Technology, University of Ljubljana, suggested the development of STRUCTRAN, a program which would convert structured code into standard FORTRAN, to be compiled into an executable file. The idea was outlined in a paper titled “STRUCTRAN”, authored by Batagelj and Egon Zakrajšek in 1975. The project was intended as a piece of cooperative work among students, during a programming course in 1975/76. As the result was not satisfactory, Zakrajšek produced the final code in 14 days at the end of the school year on a Control Data Cyber 72 mainframe computer, the main computer in the country that was also shared with others at the University of Ljubljana.
In the example below the right column was taken from the paper by Batagelj and Zakrajšek, with comment lines omitted for brevity and clarity. It is a very simple subroutine which sorts a list of integer numbers, contained in the array TAB, LENGTH long. As in FORTRAN all variables with names starting with I, J, K, L, M and N are by convention integer, unless specified otherwise, and only BOUND, CHANGE and TAB are declared. The FORTRAN version of the example (left column) contains no Go To statements but jumping is evident from the IF statements. Even to a non-programmer, the superiority of structured programming should be clearly evident.
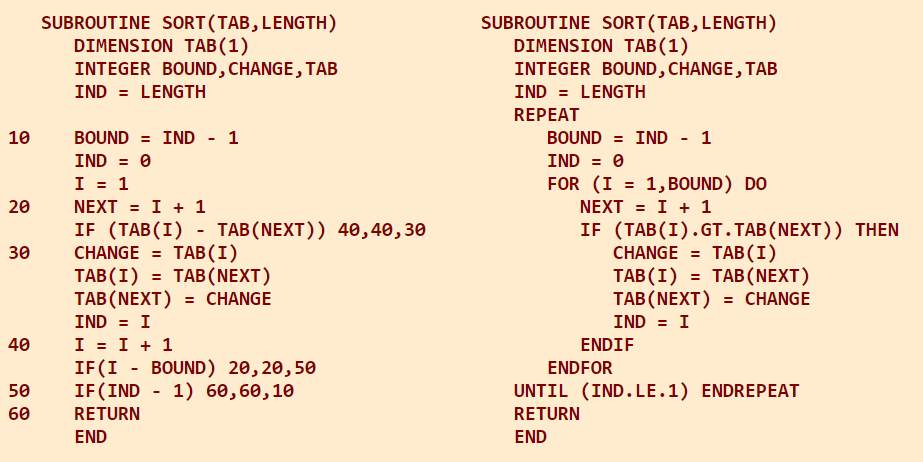
STRUCTRAN was the first widely used general-purpose software that was produced in Slovenia. It made professional life much easier for many programmers, including the author of these lines.
From BESS to EVA
The microcomputer revolution started on the other side of the Atlantic in the 1970s, and reached, to the full extent, most of the “Old World” in the early 1980s. While the first personal computers appealed to many ordinary users as gaming machines, those who were familiar with mainframes saw them as an opportunity to have a computer on your desk, a real machine they could use whenever they wanted to, not a terminal with which one could access a large computer, shared with many other users. In 1981 or early 1982, Saša Albert, a friend from the National and University Library and a technical all-rounder, brought a Sinclair ZX81 microcomputer with 1 KB of memory, a cassette recorder for external memory, and a BASIC interpreter. It was made available to me for a few days, so that I – a known computer programmer at the time – could check if something serious could be done with it. A spare small TV set was used for the monitor. The BASIC code for computing the x, y and z coordinates of cave survey points was soon written on paper, it took one full page and about ten lines on a second one. The first page would fit into the memory, the next ten lines would not. Sašo received the machine back with the following verdict: It could be used for some serious purposes, but 2 KB of memory would be required.
The next machine was a 48 KB Sinclair ZX Spectrum. Franci Ambrožič, a friend from the Faculty of Sport, had good connections in the UK and a machine was ordered in his name in July 1982. The demand was so high that the export price, which Ambrožič had to pay, was £228, as opposed to the domestic price of £175, not to mention the delivery time for foreign customers – almost half a year. In December 1982 the computer was smuggled from England to Yugoslavia, Franci enjoyed it for a few days and again, like Albert, decided to pass it to the author over the holidays around New Year, to see if something serious could be done with it. This time the answer was yes. As the machine had no text editor the author decided to make one. In about a week BESS (Basic Editor for the Sinclair Spectrum) was up and running. It was written entirely in BASIC and had 24 lines of 32 characters on screen. The interpretive nature of BASIC was most visible during text search, which took a minute per page. As an assembler was not available yet, the author wrote the text search subroutine directly in machine code, it was 50 bytes long and would search through 20 KB of text in 0.05 of a second. In 1983 and 1984 a new editor was devised, TESS (Text Editor for the Sinclair Spectrum), with 80% of the code written in Zilog Z80 assembly language, and in 1985 INES (INformation Editing System) was released, and this was commercially viable, mostly in Slovenia, although with a considerable impact in other parts of Yugoslavia. It was written almost entirely in assembly language, could work with up to 21 KB long files, had 24 lines of 64 characters (each in a 5 x 8 pixel matrix), white on black screen setting (or vice-versa), so that only 8% of TV screen was emitting harmful rays, a non-blinking cursor, no distracting permanent information on screen, smooth scrolling, and a new page of text was overwritten on the old one (not displayed on a new, blank screen). INES could also treat text lines as data records, with sorting, searching, mailing lists and several other data manipulation abilities. Graphics could be incorporated into text as an escape sequence string. There was a 68-page reference manual in Slovenian, and the editor was supported by additional utilities, such as for data entry and the sorting of longer files, up to 37 KB. English and German translations, of both the program and the manual, were also made and distributed to computer magazines in Germany and the UK. Early in 1986 INES was followed by EVE (Event Editor), also for the Sinclair Spectrum, and although this had more features it only survived long enough to get a short Quick Reference Guide. Further development was halted because the Atari ST computer had arrived, with its beautiful, all powerful Motorola 68000 processor with 16 32-bit registers.
EVE’s successor was STEVE (atari ST EVent Editor). Like its predecessors the name was an acronym, yet of a different gender. But as with ship names it was an exception to the rule, and both subsequent editors, EVA and NEVA, had female names. As with INES, the author remembered well another famous statement by Professor Dijkstra – microcomputers are not great (IFIP 1977). To get the most out of the microprocessor-powered machines – increasing the speed of the software by at least a factor of three – the programmers were forced to start programming in machine language. STEVE was 75,000 lines of such code, handling the registers directly, without the elegance and ease of structured programming.
The Slovenian version of STEVE was ready in 1986, together with a 248-page manual (a second, 290-page manual was made in 1989, with Hinko Muren), followed by Croatian and German (translated by Günther Weber) versions in 1987, another German manual by Klaus Detlef Olof and Peter Wieser in 1988 (356 pages), and the ultimate STEVE Reference Manual, with 608 pages in English, in 1989. The Atari ST machine with its megabytes of linear memory, a floppy and a hard disk, and an excellent monitor, opened new horizons, showing that ideas were possible far beyond mainframes. STEVE had quite a few novel features, one of them being that all its resources, from screen messages, keyboard layout, screen and printer fonts, to command abbreviations, were contained in a separate, STEVE-editable resource file, named STEVE.RSF. Other features included that the file size limited by available RAM, editor lines could contain text or black and white graphics, there were two graphic editors, database routines could also handle chained files where the only size limit was disk space, it had its own desktop publishing system and computer-aided instructions, as well as a graphical user interface.
STEVE was distributed in Yugoslavia, Germany, Austria, Switzerland, the Benelux countries and Scandinavia.
The early 1990s brought the demise of the Atari brand, and so the author had to change the computer platform to the PC. PCs at that time (PC/AT) were based on the Intel 80286 chip, vastly inferior to the Motorola 68000, and it made no sense – to the author and others – to program it in machine language. A suitable operating system for the PC computers, with a graphical user interface, comparable to that of Atari ST or Apple Macintosh computers, did not come until 1995.
To port STEVE with its large customer base to PC, just as it was, unchanged, would be a clever business idea. But people, especially developers, always strive to make something new, something better, more exciting. So the author, based on all his previous experience, decided to make a new, much enhanced editor, keeping all that was viable from STEVE, yet with added features which he could put to good use in his post-independent-software-developer professional life. It was named EVA, not an acronym this time, and it started as EVA for DOS in 1992 and was adapted for Windows in 1996. It is written in C language – as are the examples in Charles Petzold’s book Programming Windows 95. In C++ the author could not come close enough to the machine to implement all the features he needed, especially in the user interface. EVA has a simpler graphic editor, no computer aided instruction, limited DTP, but a true 16-bit character set with 2500 implemented characters, lines which can contain 8-bit text, 16-bit text, compressed black and white graphics and single-line bit image black and white graphics, expanded database routines with XML data format support, Optical Character Recognition (OCR) as standard (STEVE had it on demand), Part of Speech Tagging (POS) and several other language technology features such as the statistical modelling of language. One of the main attractions of STEVE, retained in EVA, was the large monospaced white screen characters on a dark background, which helped the author – who uses this latter system for most of his work, even for the construction and updating of webpages – to preserve his vision. This is quite unlike most of his colleagues who have stared at screens throughout their careers, who now typically wear glasses and have their daily dose of computer work limited, on a doctor’s recommendation, to an hour per day or less.
As of June 2022 the EVA source code is 158,211 lines long and is composed of 2,684 routines. While STEVE has 414 implemented command codes, EVA has 1,385.
NEVA
In 1998, while the author was completing his doctoral thesis at the Faculty of Electrical Engineering, University of Ljubljana, titled “Upper Bound of Entropy in Slovenian Literary Texts” his main thesis supervisor, Professor Nikola Pavešić, alerted him to the fact that the thesis length must not exceed 200 pages. However, the thesis dealt with a text corpus of some three million words and several interesting extracts deserved space in the appendices, and altogether this would exceed the page limit several times. The author was thus advised to publish the appendices on the Internet. Since a searching capability would be a welcome addition to corpus presentation, the author learned the Common Gateway Interface with its scripting language and wrote a Windows-server based search engine, also in C. This is a subset of EVA, mainly the relevant database routines with an enhanced mailing list process for the production of webpages with search results. He called it NEVA, for Networked EVA. In June 2022 NEVA had 491 routines in 25,306 lines of code.
After receiving his doctorate in June 1999 the author, employed by the Faculty of Arts, University of Ljubljana, decided to increase the core corpus installed on the faculty server – consisting of around three million words of fiction in Slovenian – with additional material that was mostly taken from the main Slovenian daily newspaper, Delo. Delo had an email service for the visually impaired people (Delo za slepe), who received a text-only copy every morning. With permission to use it for research and educational purposes he managed to increase the corpus size, now named CORTES (CORpus of TExts in Slovenian, established 1999), to some 28 million words by early 2000. This attracted the attention of the Fran Ramovš Institute of the Slovenian Language ZRC SAZU (ISJ), where the author also worked part-time. As the Faculty of Arts could not provide an institutional framework for CORTES, and as both institutions are connected in many ways, the author was easily persuaded to move the corpus to a server at the Research Centre of the Slovenian Academy of Sciences and Arts (ZRC SAZU), of which ISJ is a member. This happened in May 2000, when the corpus was renamed Nova beseda (New Word) and the entire web site to BOS – Bank Of Slovenian.
The author then moved to the ISJ to lead the newly established Laboratory for the Corpus of Slovenian Language, and continued to work part-time at the Faculty of Arts, as a teacher in the field of language technology.

Over time many of lexical resources of the ISJ were made available through the BOS web site, with some, as shown above, also presented in English (in 2015 the new Fran web site was established as the principal dictionary site of the ISJ in Slovenian). The most prominent and the most used of these resources were the Dictionary of Standard Slovenian Language (SSKJ, 1970–1991, 93,500 entries), List of Slovenian Words (BSJ, 356,000 headwords, 2006) and the Nova beseda text corpus (318 million words, 2010). While the SSKJ is the representative monolingual dictionary of Slovenian, the BSJ – compiled from SSKJ, Dictionary of Lesser Used Slovenian Words (178,457 entries), Nova beseda text corpus and the index of the Slovenian web search engine NAJDI.SI shows all the vivacity and flexibility of Slovenian in forming new words. Its size also makes sense if compared to the number of words in English. The two examples below illustrate the use of NEVA in examining two components of the name (Slovenian) Computer History Museum – Računalniški muzej.
ekomuzej fotomuzej hipermuzejski izvenmuzejski | medmuzejski megamuzej muzealec muzealen | muzealija muzealije muzealistika muzealizacija | muzealiziranje muzealizirati muzealka muzealnost | muzealogija muzealski muzealstvo muzej | muzejček muzejec muzejev muzejnik | muzejon muzejski muzejskost muzejstvo | nemuzejski obmuzejski pomuzejiti tehniškomuzejski |
The results show 32 words, nine of which also appear in the SSKJ and are highlighted. There are 20 nouns, 10 adjectives and two verbs. It is of interest to note special kinds of museums are also included in the results, ekomuzej (ecomuseum) and fotomuzej (photomuseum).
antiračunalničar antiračunalniški avtoračunalnik bančnoračunalniški bioračunalnik bioračunalniški bioračunalništvo desetračunalniški dvojnoračunalniški ekoračunalnik elektronskoračunalniški elektroračunalniški enoračunalniški fotoračunalniški hiperračunalnik informacijskoračunalniški izračunalec | izračunalnik medračunalniški megaračunalnik megaračunalo mikroračunalničar mikroračunalnik mikroračunalniški mikroračunalništvo mikroračunalo miniračunalnik miniračunalniški minisuperračunalnik mobiračunalnik multiračunalnica multiračunalnik multiračunalniški nanoračunalnik | neračunalnikar neračunalniški neračunalniško nevroračunalnik obračunalec organizacijskoračunalniški osebnoračunalniški osrednjeračunalniški polračunalnik postračunalniški predračunalniški preračunalen protiračunalniški računalce računalen računalnica računalničar | računalničarka računalničarski računalniček računalnik računalnikar računalnikarica računalnikarski računalnikov računalniški računalniškografičen računalniškopisen računalniškoprevajalski računalniškoprogramski računalniškoradiografski računalništvo računalo superračunalnik | superračunalnikar superračunalniški superračunalništvo teleračunalniški ultraračunalnik večračunalnik večračunalniški veleračunalnik veleračunalnikar veleračunalniški velikoračunalniški videoračunalniški vseračunalniški zabavnoračunalniški |
The results in this case show 82 words, and just six of these also appear in the SSKJ, as this dictionary was only compiled until 1991, before the Internet started to affect the language. Only one entry, obračunalec (settler (finance)) is suspicious, and while this could have non-computer related meaning a detailed inspection reveals that it comes from word games.
Archival challenge
Every exhibit in a museum, especially if it is made by human hand and heart, evokes many feelings, impressions and thoughts, be it the first Venus, a 55,000 year old flute or a more modern earring made of precious stones. How did the maker craft it? What brought them the idea? Who was the person that used it? All these considerations are even more vivid for computer-related exhibits, from the pieces of hardware, harbingers of the digital age, to software, intended to make the best use of these old, and not so old, machines.
{kind=link}
{kind=link}
The author’s experience with the evolution of basically the same product, a text editor which over time took under its wings many tools that helped solve a myriad of tasks which he faced in his professional life and extracurricular activities, will towards the end of this year be 40 years long. The first incarnations of this project, from BESS to INES and to a lesser extent STEVE, were made to make the most out of the machines’ limited microprocessors. Later on the hardware was fast enough to allow structured programming in a high-level language, and so the program was easier to maintain and to expand. Many user needs and suggestions were taken into account, and the dynamics of change were very fast in the first ten years, with ups and downs in the second decade, more moderate developments in the third, and occasional ones in the fourth. The code for the early versions – BESS, TESS and INES – is more or less lost. During the author’s frequent changes of residence many pieces of older media disappeared, Sinclair ZX Microdrive cartridges were not particularly reliable and also very small and easy to lose. STEVE and EVA for DOS were kept on floppy disks which are still in the author’s possession, but their condition is not known. Atari ST formatted floppies are not readable on PC machines, so assistance from the computer museum would be welcome to make a catalog of that collection. The STEVE reference manual source file, in STEVE DTP format which is also readable by EVA, was luckily still accessible, and so was converted to HTML and published on the web during the preparations for the June 2022 SRM panel discussion. The source code for EVA and NEVA, developed and maintained within Microsoft Visual C and Bloodshed’s Dev-C++ environments, is kept by the author.
How to best preserve the legacy of this project? How to make a proper presentation of it in the Slovenian Computer History Museum? And how to make it an online exhibit as well? One possibility, to begin with, is its inclusion in the Internet Archive Software Collection, yet a much better option would be to keep it functional. Unlike most of our digital history, EVA and NEVA are both still operational and used.
The role of a librarian has changed from a person in pre-digital times who could tell an interested user where, and in which book, to look for certain information, to someone who can advise a user where to look on the Internet for what he or she needs. So the role of a museum curator and museum guide should change, too. With better, in-depth knowledge about a software exhibit, it can be presented to the museum visitors in a vivid, interactive fashion, incomparably better than any description presented online. Even more so if the software is still operational, like EVA and NEVA. Such a curator would also be a valuable source of information to people who have to tackle a problem that was presumably already solved, yet the solution is not generally known or is poorly or not at all documented on the Internet.
To facilitate the making of such a museum presentation it should be prepared by someone well acquainted with the subject, ideally the author, and by the museum curator who will deliver it. The process would certainly take time, but it would be the time well spent.
The presentation of software as an online exhibit is a connected story, but again a different one. The Internet Archive Software Collection, though valuable, does not present software in a unified, curated fashion, and the sources are also not there (the SourceForge open-source platform, where the number of entries is smaller by two orders of magnitude, is not an archive collection). To make EVA and NEVA an online museum exhibit would require a medium very much like Wikisource, but adapted to the presentation of software. Unlike books, where the reader can enjoy the artistic reflection of human life in fiction by reading it page by page, software can be enjoyed by watching its performance with a set of data, from a tiny seed in a random number generator to a text processor which can handle the four billion words of Wikipedia articles (April 2022).